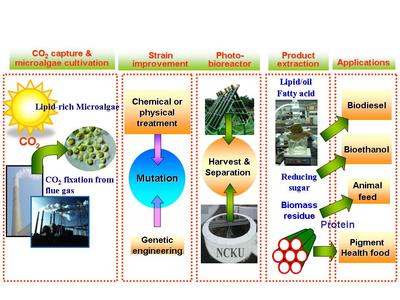
上海科技大學劉佳與姜標團隊合作開發原位光激活生物正交偶聯反應,推動生物技術新突破
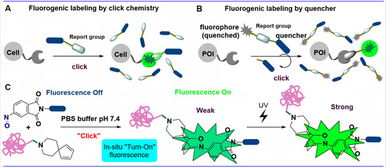
上海科技大學的劉佳教授與姜標教授研究團隊,攜手合作伙伴,在生物技術領域取得重要進展,成功開發出一種原位光激活的生物正交偶聯反應。這一創新技術通過在生物體內或細胞環境中利用光控機制,實現高選擇性、高效能的分子偶聯,為蛋白質標記、藥物靶向遞送和活體成像等應用提供了新工具。該研究不僅優化了反應條件,確保在生理環境下兼容性,還通過實驗驗證了其低毒性和高時空分辨率的優勢,有望加速生物醫學研究與藥物開發進程。這一成果已發表在相關學術期刊,展示了中國科研團隊在生物正交化學領域的領先實力。
如若轉載,請注明出處:http://www.koreatong.cn/product/16.html
更新時間:2026-06-14 04:03:23